
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 동시성문제
- MDC
- 트랜잭션
- Transactio
- HikariCP
- 살아남았다.
- resilience4j
- Thread
- circuitbreaker
- Gateway
- Kotlin
- 우테코
- Spring Batch
- DispatcherServlet
- spirng
- oauth
- 오어스
- 우아한테크코스
- AOP
- 최종 합격
- redis
- 테스트코드
- Elk
- 우테코 5기
- JWT
- tomcat
- 톰캣
- Spring cloud gateway
- 커넥션 풀
- 우아한 테크 코스
- Today
- Total
코딩은 내일부터
동글 프로젝트 쿼리 개선기 본문

이번 포스팅에서 커버링 인덱스와 N+1문제를 Fetch Join을 사용해서 개선한 과정을 작성해 보겠다!!
1. 글의 내용 가져오는 쿼리 성능 개선

프로젝트를 진행하면서 성능 최적화를 위해 “지연 로딩”(Lazy Loading)전략을 사용해서 DB의 데이터를 가져왔다.
위에 writing 도메인을 보면 writing이라는 엔티티 안에 필드로 Blocks를 가지고 있다.

왜냐하면 위 사진과 같이 글 내부에 형태(h1, h2,… 리스트 등등)가 여러 개로 구성될 수 있기 때문이다.
(파란색 블록이 1개의 블록을 나타낸다.)
즉, 하나의 글 안에 여러 개의 블록을 가지고 있는 1:N관계로 DB에 저장하고 있고,
블록마다 저장되는 형태도 다름으로 다음과 같이 여러 형태가 있고 Block으로 추상화를 적용하였다.

이러한 지연로딩은 글(writing)의 제목 수정, 글 제목 가져오기 등등 Lazy Loading을 통해 글의 내용물이 아닌 정보만 필요할 때 성능의 이점을 차지할 수 있었지만,

위와 같이 1번. 글(writing)을 찾고,
2번. 클라이언트에서 html형태로 보여주기 위해 랜더링을 진행할 때
블록에 맞는 html형태로 랜더링 중 NormalBlock에 getStyles() 메서드를 실행하면
select 쿼리가 나가 Blocks에서 타입이 NormalBlock의 개수만큼 styles을 select를 하고 있다.
성능 최적화를 하려고 적용시킨 지연 로딩 전략이 오히려 다음과 같이 n+1문제가 발생하고 있었다...
다음은 실제 글을 가져오고 랜더링과정까지의 실제 쿼리이다.
실제 쿼리(많이 길어요…)
select
*
from
writing w
where
w.member_id = ?
and w.id = ?
and w.status != 'DELETED'
select
b1_0.writing_id,
b1_0.id,
b1_0.dtype,
b1_0.block_type,
b1_0.created_at,
b1_0.depth,
b1_0.updated_at,
b1_1.language,
b1_1.raw_text,
b1_2.raw_text,
b1_3.image_caption,
b1_3.image_url,
b1_4.raw_text,
b1_4.id
from
block b1_0
left join
code_block b1_1
on b1_0.id=b1_1.id
left join
horizontal_rules_block b1_2
on b1_0.id=b1_2.id
left join
image_block b1_3
on b1_0.id=b1_3.id
left join
normal_block b1_4
on b1_0.id=b1_4.id
where
b1_0.writing_id=?
select
s1_0.normal_block_id,
s1_0.id,
s1_0.created_at,
s1_0.end_index,
s1_0.start_index,
s1_0.style_type,
s1_0.updated_at
from
style s1_0
where
s1_0.normal_block_id=?
Hibernate:
select
s1_0.normal_block_id,
s1_0.id,
s1_0.created_at,
s1_0.end_index,
s1_0.start_index,
s1_0.style_type,
s1_0.updated_at
from
style s1_0
where
s1_0.normal_block_id=?
Hibernate:
select
s1_0.normal_block_id,
s1_0.id,
s1_0.created_at,
s1_0.end_index,
s1_0.start_index,
s1_0.style_type,
s1_0.updated_at
from
style s1_0
where
s1_0.normal_block_id=?
Hibernate:
select
s1_0.normal_block_id,
s1_0.id,
s1_0.created_at,
s1_0.end_index,
s1_0.start_index,
s1_0.style_type,
s1_0.updated_at
from
style s1_0
where
s1_0.normal_block_id=?
Hibernate:
select
s1_0.normal_block_id,
s1_0.id,
s1_0.created_at,
s1_0.end_index,
s1_0.start_index,
s1_0.style_type,
s1_0.updated_at
from
style s1_0
where
s1_0.normal_block_id=?
Hibernate:
select
s1_0.normal_block_id,
s1_0.id,
s1_0.created_at,
s1_0.end_index,
s1_0.start_index,
s1_0.style_type,
s1_0.updated_at
from
style s1_0
where
s1_0.normal_block_id=?
Hibernate:
select
s1_0.normal_block_id,
s1_0.id,
s1_0.created_at,
s1_0.end_index,
s1_0.start_index,
s1_0.style_type,
s1_0.updated_at
from
style s1_0
where
s1_0.normal_block_id=?
Hibernate:
select
s1_0.normal_block_id,
s1_0.id,
s1_0.created_at,
s1_0.end_index,
s1_0.start_index,
s1_0.style_type,
s1_0.updated_at
from
style s1_0
where
s1_0.normal_block_id=?
Hibernate:
select
s1_0.normal_block_id,
s1_0.id,
s1_0.created_at,
s1_0.end_index,
s1_0.start_index,
s1_0.style_type,
s1_0.updated_at
from
style s1_0
where
s1_0.normal_block_id=?
Hibernate:
select
s1_0.normal_block_id,
s1_0.id,
s1_0.created_at,
s1_0.end_index,
s1_0.start_index,
s1_0.style_type,
s1_0.updated_at
from
style s1_0
where
s1_0.normal_block_id=?
Hibernate:
select
s1_0.normal_block_id,
s1_0.id,
s1_0.created_at,
s1_0.end_index,
s1_0.start_index,
s1_0.style_type,
s1_0.updated_at
from
style s1_0
where
s1_0.normal_block_id=?
Hibernate:
select
s1_0.normal_block_id,
s1_0.id,
s1_0.created_at,
s1_0.end_index,
s1_0.start_index,
s1_0.style_type,
s1_0.updated_at
from
style s1_0
where
s1_0.normal_block_id=?
Hibernate:
select
s1_0.normal_block_id,
s1_0.id,
s1_0.created_at,
s1_0.end_index,
s1_0.start_index,
s1_0.style_type,
s1_0.updated_at
from
style s1_0
where
s1_0.normal_block_id=?
Hibernate:
select
s1_0.normal_block_id,
s1_0.id,
s1_0.created_at,
s1_0.end_index,
s1_0.start_index,
s1_0.style_type,
s1_0.updated_at
from
style s1_0
where
s1_0.normal_block_id=?
Hibernate:
select
s1_0.normal_block_id,
s1_0.id,
s1_0.created_at,
s1_0.end_index,
s1_0.start_index,
s1_0.style_type,
s1_0.updated_at
from
style s1_0
where
s1_0.normal_block_id=?
Hibernate:
select
s1_0.normal_block_id,
s1_0.id,
s1_0.created_at,
s1_0.end_index,
s1_0.start_index,
s1_0.style_type,
s1_0.updated_at
from
style s1_0
where
s1_0.normal_block_id=?
Hibernate:
select
s1_0.normal_block_id,
s1_0.id,
s1_0.created_at,
s1_0.end_index,
s1_0.start_index,
s1_0.style_type,
s1_0.updated_at
from
style s1_0
where
s1_0.normal_block_id=?
Hibernate:
select
s1_0.normal_block_id,
s1_0.id,
s1_0.created_at,
s1_0.end_index,
s1_0.start_index,
s1_0.style_type,
s1_0.updated_at
from
style s1_0
where
s1_0.normal_block_id=?
Hibernate:
select
s1_0.normal_block_id,
s1_0.id,
s1_0.created_at,
s1_0.end_index,
s1_0.start_index,
s1_0.style_type,
s1_0.updated_at
from
style s1_0
where
s1_0.normal_block_id=?
Hibernate:
select
s1_0.normal_block_id,
s1_0.id,
s1_0.created_at,
s1_0.end_index,
s1_0.start_index,
s1_0.style_type,
s1_0.updated_at
from
style s1_0
where
s1_0.normal_block_id=?
Hibernate:
select
s1_0.normal_block_id,
s1_0.id,
s1_0.created_at,
s1_0.end_index,
s1_0.start_index,
s1_0.style_type,
s1_0.updated_at
from
style s1_0
where
s1_0.normal_block_id=?
Hibernate:
select
s1_0.normal_block_id,
s1_0.id,
s1_0.created_at,
s1_0.end_index,
s1_0.start_index,
s1_0.style_type,
s1_0.updated_at
from
style s1_0
where
s1_0.normal_block_id=?
Hibernate:
select
s1_0.normal_block_id,
s1_0.id,
s1_0.created_at,
s1_0.end_index,
s1_0.start_index,
s1_0.style_type,
s1_0.updated_at
from
style s1_0
where
s1_0.normal_block_id=?
Hibernate:
select
s1_0.normal_block_id,
s1_0.id,
s1_0.created_at,
s1_0.end_index,
s1_0.start_index,
s1_0.style_type,
s1_0.updated_at
from
style s1_0
where
s1_0.normal_block_id=?
Hibernate:
select
s1_0.normal_block_id,
s1_0.id,
s1_0.created_at,
s1_0.end_index,
s1_0.start_index,
s1_0.style_type,
s1_0.updated_at
from
style s1_0
where
s1_0.normal_block_id=?
Hibernate:
select
s1_0.normal_block_id,
s1_0.id,
s1_0.created_at,
s1_0.end_index,
s1_0.start_index,
s1_0.style_type,
s1_0.updated_at
from
style s1_0
where
s1_0.normal_block_id=?
Hibernate:
select
s1_0.normal_block_id,
s1_0.id,
s1_0.created_at,
s1_0.end_index,
s1_0.start_index,
s1_0.style_type,
s1_0.updated_at
from
style s1_0
where
s1_0.normal_block_id=?
Hibernate:
select
s1_0.normal_block_id,
s1_0.id,
s1_0.created_at,
s1_0.end_index,
s1_0.start_index,
s1_0.style_type,
s1_0.updated_at
from
style s1_0
where
s1_0.normal_block_id=?
Hibernate:
select
s1_0.normal_block_id,
s1_0.id,
s1_0.created_at,
s1_0.end_index,
s1_0.start_index,
s1_0.style_type,
s1_0.updated_at
from
style s1_0
where
s1_0.normal_block_id=?
Hibernate:
select
s1_0.normal_block_id,
s1_0.id,
s1_0.created_at,
s1_0.end_index,
s1_0.start_index,
s1_0.style_type,
s1_0.updated_at
from
style s1_0
where
s1_0.normal_block_id=?그래서 글을 랜더링을 하기 전에만 글의 모든 내용을 가져오도록 하기 위해 fetch join을 적용하기로 했다.
Fetch Join이란?
fetch join은 SQL에서 사용하는 조인이 아니고 성능최적화를 위해 JPQL에서 제공하는 기능이다.
다시 말해 fetch join의 주요 목적은 관련된 엔티티나 컬렉션을 즉시 로직하기 위한 것이다.
실제 코드에 적용
Hibernate:
select
*
from
writing w
where
w.member_id = ?
and w.id = ?
and w.status != 'DELETED'
Hibernate:
select
b1_0.writing_id,
b1_0.id,
b1_0.dtype,
b1_0.block_type,
b1_0.created_at,
b1_0.depth,
b1_0.updated_at,
b1_1.language,
b1_1.raw_text,
b1_2.raw_text,
b1_3.image_caption,
b1_3.image_url,
b1_4.raw_text,
b1_4.id
from
block b1_0
left join
code_block b1_1
on b1_0.id=b1_1.id
left join
horizontal_rules_block b1_2
on b1_0.id=b1_2.id
left join
image_block b1_3
on b1_0.id=b1_3.id
left join
normal_block b1_4
on b1_0.id=b1_4.id
where
b1_0.writing_id=?원래 쿼리는 위와 같이 삭제되지 않은 글을 select 하고 그다음으로 글이 가지고 있는 Blocks를 select 해서 가져온다.(2번 select)
글을 랜더링 할 때는 무조건 Blocks를 모두 가져와야 하기 때문에
Fetch Join을 적용한 findByWithBlocks메서드를 구현하여 다음과 같이 하나의 쿼리로 줄였다.

다음으로 현재 NormalBlock이 가지고 있는 Styles를 가져오는 쿼리가 밑에처럼 n번 나가고 있었다.
Hibernate:
select
s1_0.normal_block_id,
s1_0.id,
s1_0.created_at,
s1_0.end_index,
s1_0.start_index,
s1_0.style_type,
s1_0.updated_at
from
style s1_0
where
s1_0.normal_block_id=?
Hibernate:
select
s1_0.normal_block_id,
s1_0.id,
s1_0.created_at,
s1_0.end_index,
s1_0.start_index,
s1_0.style_type,
s1_0.updated_at
from
style s1_0
where
s1_0.normal_block_id=?
.
.
.
.
. select normal_block의 스타일
.
.
.
.
n번 select
그래서 findStyleByNormalBlocks메서드 내부에 normalBlocks을 찾는 코드를 추가하고


findStylesForBlocks라는 Fetch Join을 적용한 메서드를 만들어 NormalBlock의 스타일을 한 번에 찾아오도록 수정했다.
이렇게 쿼리를 수정해서 다음과 같이 여러 번의 쿼리를 제거하고 2번의 쿼리만으로 글을 불러오도록 개선할 수 있었다.

2. 글의 세부 내용(발행 정보)을 가져오는 쿼리 성능 개선
동글 서비스에서 카테고리를 클릭하면 카테고리 안에 있는 글의 제목과 발행한 블로그 플랫폼 등등 글의 대한 정보를 확인할 수 있는데

글의 정보를 가져오는 하나의 작업에서 사용하는 쿼리를 살펴보면

3,4,5번을 보면 발행한 블로그의 정보, 태그 목록의 정보를 가져올 때
글의 개수*2만큼 select 쿼리를 실행하는 거를 볼 수 있다.
(글의 발행정보, 발행한 태그정보 각각 n+1문제가 발생하고 있다.)
이러한 문제 또한 위에 normalBlock의 style을 가져온 거처럼 Fetch Join을 적용해서 쿼리를 개선할 수 있다.
문제의 코드
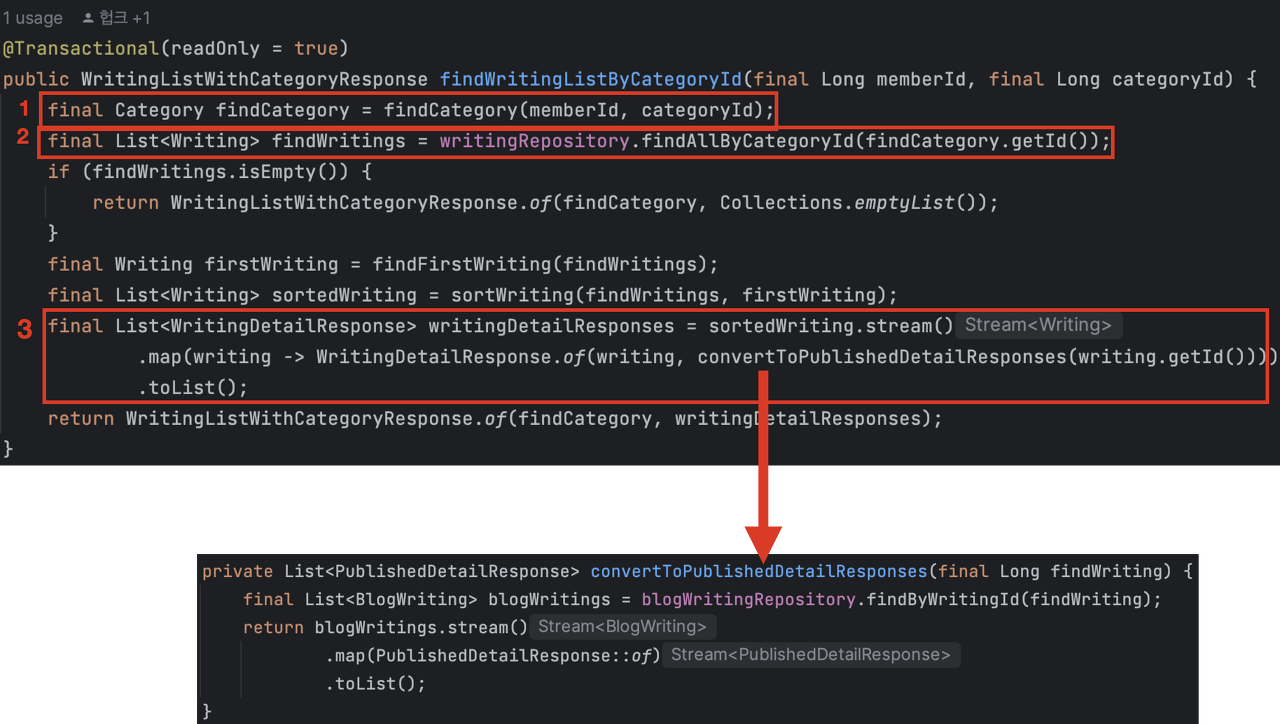
문제의 코드를 보면 1,2번까지는 문제가 없다.
3번을 보면 정렬된 sortedWriting에 stream을 사용해서 Response를 만들고 있는데
이때 글의 개수만큼 convertToPublishedDetailResponses메서드를 실행시켜
BlogWriting을 select를 하고(n+1 발생)

BlogWriting필드에서 tag정보는 @ElementCollection 어노테이션을 사용하고 있다.
@ElementCollection 어노테이션은 기본적으로 지연로딩이기 때문에 getTags() 메서드를 호출할 때마다 쿼리가 실행돼서
n+1문제가 발생하여 총 2번의 n+1문제가 발생하고 있었다.

그래서 다음과 같이 코드를 수정하였는데 먼저 findWithBlogWritings메서드를 통해 발행한 블로그 정보와 tags의 정보를 모두 가져오고 groupingBy메서드를 사용해서 Map <writing, list> 형식으로 변경하여 Response를 만드는 형태로 로직을 수정하였다.
이렇게 변경한 로직으로 쿼리를 다시 실행해 보면 2번의 쿼리로 개선할 수 있었다.
select
w1_0.id,
w1_0.category_id,
w1_0.created_at,
w1_0.member_id,
w1_0.next_writing_id,
w1_0.status,
w1_0.title,
w1_0.updated_at
from
writing w1_0
where
w1_0.category_id=?
and w1_0.status=?
select
b1_0.id,
b2_0.id,
b2_0.blog_type,
b2_0.created_at,
b2_0.updated_at,
b1_0.created_at,
b1_0.published_at,
t1_0.blog_writing_id,
t1_0.tags,
b1_0.updated_at,
b1_0.url,
b1_0.writing_id
from
blog_writing b1_0
left join
blog b2_0
on b2_0.id=b1_0.blog_id
left join
blog_writing_tags t1_0
on b1_0.id=t1_0.blog_writing_id
where
b1_0.writing_id in (?,?,?)
@EntityGraph를 사용해 보면 어떨까?
동글의 서비스에 사용되는 쿼리를 하나하나 살펴보면서 n+1문제가 발생하는 부분에 Fetch Join을 써서 해결을 하였다.
프로젝트에서 Fetch Join을 써서 바꿔봤지만 @EntityGraph 어노테이션을 통해서도 Fetch Join을 할 수 있다.

위에서 사진처럼, @EntityGraph 어노테이션을 사용하여 변경하는 것이 가능하다.
그러나 이 어노테이션을 사용할 때 주의할 점은, @EntityGraph어노테이션은 오직 LEFT JOIN만 수행할 수 있다는 것이다.
따라서 상황에 따라 적절한 JOIN 전략을 고려하여 사용하면 될 거 같다!!
3. 커버링 인덱스 적용
MySQL의 경우 인덱스 안에 있는 데이터를 사용할 수 있다.
이를 잘 이용하면 실제 데이터까지 접근할 필요가 없다. 즉, 테이블에 접근하지 않아도 된다.
커버링 인덱스는 쿼리를 충족하는데 필요한 모든 데이터를 갖는 인덱스를 뜻한다.
커버링 인덱스를 잘 쓰면(특히, 대용량 데이터 처리 시), 조회 성능을 상당 부분 높일 수 있다.

현재 동글 프로젝트에서 로그인과 회원가입을 할 때 위와 같은 쿼리를 날리고 있다.
하지만 member id만 필요한 상태이므로 커버링 인덱스를 적용할 수 있을 거 같아 수정을 해보았다.
가정

사용자가 1만 명일 때를 예를 들어 더미데이터 넣었다.

실행결과를 보면 커버링 인덱스가 적용되지 않았고, 평균 58.6ms가 걸린 걸 볼 수 있다.

커버링 인덱스가 사용되도록 위와 같은 MemberInfo라는 Dto를 사용하여 find 메서드를 변경했다.

그 결과 extra를 보면 커버링 인덱스를 사용하는 거를 볼 수 있고 58.6ms → 44.2ms로 24.57%의 성능 향상을 기대할 수 있다.
14ms의 작은 성능향상이 있었지만, 커버링 인댁스가 적용되어 쿼리가 빨리 실행되면 CPU, 메모리 등의 자원도 더 효율적으로 사용되어 전체 시스템의 부하가 줄어들 수 있고 동시에 수천, 수만의 쿼리가 실행될 수 있는 환경에서는 14.4ms의 감소가 큰 차이를 만들 수 있을 거 같아 커버링 인덱스를 적용해 보았다!
Fatch Join을 적용한 코드
https://github.com/woowacourse-teams/2023-dong-gle/pull/426
[BE] refactor: 여러번 쿼리나가는 글 가져오기, 글 발행정보 쿼리 수정 by ingpyo · Pull Request #426 · woow
🛠️ Issue close #425 ✅ Tasks 글을 가져올때 글의 블럭마다 select쿼리를 날리는 로직 in절 추가 블로그 발행 여부 쿼리 JOIN FETCH추가 ⏰ Time Difference 2
github.com
커버링 인덱스를 적용한 코드
https://github.com/woowacourse-teams/2023-dong-gle/pull/424
[BE] refactor: 회원조회할때 커버링 인덱스가 적용되도록 수정 by ingpyo · Pull Request #424 · woowacourse-te
🛠️ Issue close #421 ✅ Tasks memberAuth DTO도입 후 로그인 로직에 적용 ⏰ Time Difference 1
github.com
'우아한 테크 코스(우테코) > 우테코 공부' 카테고리의 다른 글
| 분산락(Named Lock)으로 동시성 관리하기 (3) | 2023.10.13 |
|---|---|
| 동글 프로젝트 테스트 코드 개선 및 최적화 (7) | 2023.10.01 |
| LinkedList로 글과 카테고리의 순서 구현했을 때 동시성 제어 (2) | 2023.09.16 |
| 파사드 패턴으로 외부 API와 DB 트랜잭션 범위 분리하기 (0) | 2023.09.14 |
| 동시성 문제 해결을 위한 회원가입 기능 개선 (5) | 2023.09.11 |



